


Wot's Uh... The Deal With How We Pick Antidepressants and Antipsychotics Pt. 1
Part 1 of an essay on prescribing narratives in psychiatry

I’ve been neglecting the antidepressants.
Mostly this is reflective of where my interests lie. There’s just something about psychosis and mania that I find alluring, and the side-effects and available formulations of the antidopaminergics are so pronounced and varied that selection feels quite meaningful.
Antidepressants, on the other hand, don’t just seem to interest me in the same way, though they don’t seem to interest anyone else very much either… except maybe for the MAOIs. Antidepressants seem to be selected based on the idiosyncratic beliefs of whomever is prescribing them, but even then are generally treated as interchangeable except for their side-effect profiles.
In any case, I haven’t spent nearly as much time learning about their nuances1. This is, admittedly, pretty dumb given that I have prescribed far more antidepressants than anything else.
So, this is my attempt to get a little more of a grasp on what the best available evidence says about picking antidepressants. I’ve decided to compare them alongside the antidopaminergics - which I am much more familiar with - to better calibrate my thought process.
The Antidepressants
In my experience, they get chunked out like so:
SSRIs/SNRIs: First line. Treated as almost identical to one another in terms of efficacy, though if you put the screws to someone to pick between the categories they will usually say something about having read that SNRIs are marginally more effective. Usually selected based on side-effect profile.
Atypicals: Basically mirtazapine, bupropion, sometimes vortioxetine, almost never trazodone. Also first-line depending on target symptoms. Generally spoken about as similarly efficacious as the SSRIs/SNRIs.
TCAs: Considered to be more effective than the atypicals or SSRIs/SNRIs, but generally only used after multiple failed trials of a SSRI/SNRI or atypicals due to side-effects and high lethality in overdose.
MAOIs: They have a very Old Testament God vibe; medications of Great but Terrible Power whose true names are so obscure2 that they are referred to only by their class. Unfortunately, not many have read the MAOIs’ New Testament - a blog called Psychotropical written by Dr. Ken Gilman - in which the MAOIs have become a much more forgiving and kind medication class, mostly due to advances in food preservation techniques3.
Suchting et al.
Suchting et al.4 2021 does a meta-analysis of 52 studies with 6,462 individuals who have depressive disorders across 14 different antidepressants. It actually isn’t all that supportive of the MAOIs as some sort of uniquely efficacious class of antidepressants as you can see below.

The wide confidence intervals here are indicative of relatively sparse and low-quality data about the MAOIs. Moclobemide - a reversible MAOI that was never marketed in the US - and selegiline have the most studies behind them, but I think you’d be hard-pressed to argue they’re uniquely efficacious based on this data.
Cipriani et al.
Let’s instead look at this meta-analysis of patients with major depressive disorder in the April 2018 edition of the The Lancet by Cipriani et al.. They analyze 522 trials of 116,477 patients across 21 different medications. They do not include the MAOIs, but their analysis is more complete in its data collection for the other antidepressants.
Amitriptyline, a TCA5, sits atop the heap, but the rest of the list looks like a pretty close race between different SSRIs, SNRIs, TCAs, and other atypicals.

Let me contextualize the outcomes here a bit.
Efficacy in both studies was defined as a >50% reduction in whatever standardized scale the study was using, which was mostly the 17 item Hamilton Depression Rating Scale (HAM-D 176) and is graded as follows:
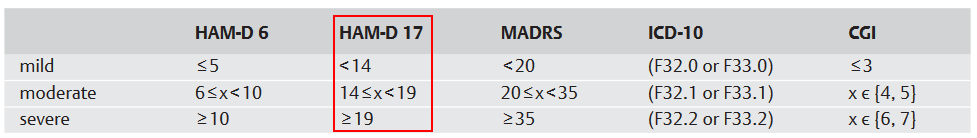
The mean baseline HAM-D 17 score7 of a participant was 25.7 (sd = 3.97), which means that:
99.8% of participants had HAM-D’s that were at least in the moderate severity range (i.e. a score >=14)
95% of participants had HAM-D 17 scores that indicated severe depression
Cutting the average HAM-D 17 score in half - to 12.9 - would put a patient into the “mild” depression range
Overall Response Numbers
I took the ORs and did a very basic simulation in Excel with 1000 patients given placebo and 1000 given an antidepressant. I set the placebo response rate at 35%, which is what the literature suggests it is for the antidepressants.
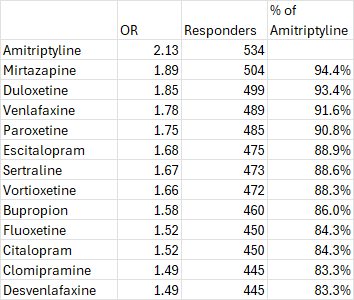
The differences here are pretty modest, right? Especially when you consider that there are a lot of overlapping confidence intervals between these study drugs. Sure fluoxetine looks 17% worse, but is that so much worse that you’d consider amitriptyline and all of its side-effects first? Probably not.
Things start to look a little different, though, when you remember that a large percentage of these responders would have improved even if they had just gotten placebo.
Drug Responders
In this next table, I used the OR to calculate how many responders you would see in the treatment group and then subtracted 350 from that number to correct for the placebo response. This leave us with what I will call ‘drug responders.’

Suddenly the differences between antidepressants seems a bit more meaningful.
To put this into English:
If a doctor treated 1000 patients with amitriptyline, they would expect on average8 to see 534 responders (i.e. people whose scores improve by >50%), but only 184 of those responders would be due to the amitriptyline (i.e. drug responders); 350 of them would’ve gotten better if we had just given them placebo9.
In contrast, if that doctor gave 1000 patients bupropion, you’d see 460 of them get better, but only 110 of them would’ve been due to the bupropion. That’s 74 less (40% fewer) drug responders relative to amitriptyline!
Number Needed to Treat
You can also think about this in terms of the Number Needed to Treat (NNT). In other words, how many patients do you need to treat to get one additional responder relative to placebo?
Depending on the context, NNT can be a bit confusing, so I just want to emphasize that these numbers are relative to placebo. To properly interpret these numbers, you need to imagine that every patient is getting a placebo (not the same as getting nothing!), and the NNT describes how many patients you would need to put on each of these drugs instead to get one additional person with a >50% decline in their HAM-D 17 scores.

Again I think that this suggests that there are real practical differences in antidepressant selection here.
Head-To-Head
I should probably mention that in that same paper Cipriani et al. also did a head-to-head comparison between all of these drugs and found:
Agomelatine, amitriptyline, escitalopram, mirtazapine, paroxetine, venlafaxine, and vortioxetine were more effective than other antidepressants (ORs ranging between 1·19 and 1·96), whereas fluoxetine, fluvoxamine, reboxetine, and trazodone were among the least efficacious drugs (ORs ranging between 0·51 and 0·84)
This generally tracks my ad hoc analysis above, but my opinion is that it probably makes more sense to mostly ignore this head-to-head analysis and use their primary analysis above - less assumptions and higher-quality data overall.
A Brief Aside on Acceptability
Since we’re on the topic, acceptability (i.e. dropout rate) does not suggest the sort of clear differentiation in intolerable side-effects between the various antidepressants that is part of psychiatric lore either.
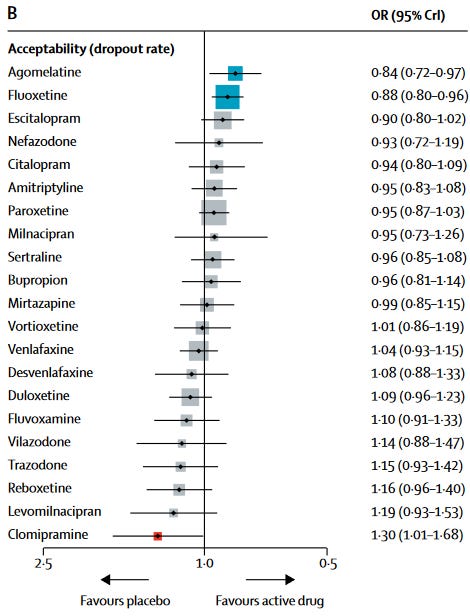
I think it’s pretty interesting that amitriptyline is solidly in the middle of the pack given how frequently we talk about the TCAs as so sedating as to almost be useless for the majority of patients. Remember that dropout rate is really a product of side-effect burden and efficacy; if a drug is effective, it’ll increase the side-effect burden that you’re willing to tolerate.
This last idea might explain, in part, why we focus so much on side-effects with antidepressants. If you’re treating a lot of mild/moderate symptoms (which is the bread-and-butter of a lot of psych, more on this later), patients will be less likely to find side-effects worth the improvements and so we try and maximize tolerability.
The Antidopaminergics
In contrast to the antidepressants, psychiatrists generally have strong opinions about which antipsychotics are “strong” and which are “weak.” “Strong” is generally used as shorthand to mean preferred for acute psychosis and/or patients with prominent “positive” symptoms (i.e. hallucinations, delusions, disorganized thought).
Some examples:
“Strong”: Clozapine, olanzapine, haloperidol, risperidone
“Weak”: Ziprasidone, lurasidone, aripiprazole, quetiapine
Theoretically, the branding of the partial agonists like aripiprazole as “weak” makes sense to me if we didn’t have any additional information… but of course we do.
Huhny I’m Home
…sorry.
Let’s take a peek at another meta-analysis from The Lancet. This time it’s Huhn et al. 2019:

We can see that these “strong” and “weak” categories actually seem to hold up to some extent, but the absolute differences look pretty tiny no? What’s the difference between a SMD of -0.56 and a SMD of -0.42 really?
Statistics Time, Sorry
This comparison uses standard mean differences (SMDs) which you probably know better as Cohen’s d10, which you probably know even better as “effect size.”
I am not a Statistics Wizard, so thank god Stefan Leucht and his friend et al. wrote an article specifically to explain the 13 different ways we can conceptualize effect size for the antidopaminergics. They include this lovely figure that illustrates what a SMD change does to a standard distribution quite nicely.

The Positive And Negative Symptom Scale (PANSS), Briefly
The PANSS is the most commonly used clinical rating scale for evaluating symptoms in primary psychosis. It was created as an expansion to the Brief Psychiatric Rating Scale (BPRS) which is an 18 question inventory with relatively nebulous scoring requirements.
The PANSS consists of three subscales:
Positive Scale: 7 questions about the positive symptoms of schizophrenia (e.g. hallucinations, delusions, disorganization). Max score = 49
Negative Scale: 7 questions about the negative symptoms of schizophrenia (e.g. social withdrawal, apathy, difficulty with abstraction). Max score = 49
General Psychopathology Scale: 16 questions about symptoms that don’t neatly fall into either category. Some questions ask about general symptoms that are not necessarily related to psychosis (e.g. depression, attention, impulsivity), while others are more directly related (e.g. unusual thought content). Max score = 112.
Questions are given a score between 1 (not present) and 7. Each question has detailed explanations for each individual score, for example a score of 5 on question P3. “Hallucinatory behavior” is described as so:
5 Moderate severe - Hallucinations are frequent, may involve more than one sensory modality, and tend to distort thinking and/or disrupt behavior. Patient may have a delusional interpretation of these experiences and respond to them emotionally and, on occasion, verbally as well.
Scores range between 30 and 210, higher numbers indicate more severe symptoms. You can see a full version of the scale here.
The Leucht paper points out that, based on two big meta-analyses (Huhn et al. above and Leucht et al. 201711) the mean baseline PANSS score in these studies is 9512 with a standard deviation of 20.
To put it all together, that means we would expect to see the following changes in PANSS scores in the average patient based on the Huhn paper:
Clozapine: -17.8
Olanzapine: -11.2
Risperidone: -11
Quetiapine: -8.4
Aripiprazole: -8.2
Lurasidone: -7.2
That’s great, but I still haven’t explained what these deltas correspond to clinically. Stefan Leucht and et al. (who you may be familiar with by now) wrote a paper literally called What does the PANSS mean? in 2005. They compared changes in PANSS scores to ratings on the Clinical Global Impressions (CGI) scale.
The CGI, Briefly
The CGI has a symptom scale (The CGI-S) and an improvement scale (CGI-I). These scales are meant to identify how a physician seeing a patient outside of a study environment would evaluate them. We’re going to be talking about these scores a decent amount, so I’ve included two images below that describe what each CGI score (roughly) corresponds to.


Empiricists will probably shudder at the subjectivity here, but I think the CGI makes a lot of sense for subjective symptoms where you can’t trust the patient to reliably self-report. It also reflects how we evaluate drug efficacy in the real-world. Very few psychiatrists - if any - adjust treatment for schizophrenia based on closely monitored PANSS scores.
Anyway, back to the paper. Leucht and his co-authors matched up PANSS scores (range: 30-210) with CGI-S scores by asking clinicians to rate patients on the CGI-S and then comparing what PANSS scores correlated with CGI-S scores:
CGI-S 3 / Mild: 58
CGI-S 4 / Moderate: 75
CGI-S 5 / Marked: 95
CGI-S 6 & 7 / Severe: >115
Leucht et al. found that for patients to be considered “minimally improved” (i.e. to score a 3 on the CGI-I) they needed to show a decrease in their PANSS score of 19-28% depending on the timeframe. If we take our average study participant with a PANSS of 95 this means a decrease between 18-27 points. “Much improved” reflected between a 40-53% decrease in PANSS; 38-50 points. “Very much improved” reflected a 71-81% decrease; 67-77 points.
This means that even for clozapine - the most efficacious antidopaminergic we have available - the average patient is just barely getting into “minimally improved” territory, which - remember - means “no clinically meaningful reduction of symptoms.”
To be fair, there’s some odd stuff going on here with the correspondence between the rating scales. If we take the average PANSS change needed for “minimal” improvement on the CGI, that’s 22.5, which would knock our average patient with a ‘marked’ CGI-S score down to a 72.5, which would put them at a “moderate” CGI-S score. This represents a change from symptoms that “distinctly impair functioning… or cause intrusive levels of distress” to symptoms that cause “noticeable, but modest functional impairment or distress.” This seems pretty incompatible with the description of “minimal” improvement as “slightly better, with no clinically meaningful reduction of symptoms.”
(Yet another) Leucht et al. meta-analysis this time from Oct. 2017, has a nice table illustrating how just how few individuals are at least “much improved” (i.e. are judged to have a clinically significant improvement) with antidopaminergics.
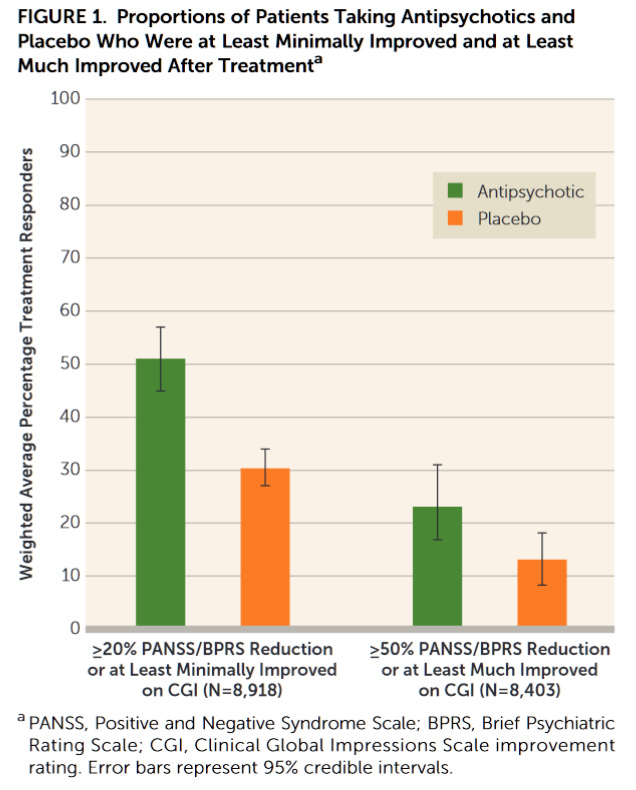
Those “strong” and “weak” categories aren’t looking so clinically distinct anymore, are they?
This Is The Bit Where I Tease Part 2.
Ok - so let’s review where we’re at.
Antidepressants are generally treated as interchangeable in terms of efficacy, except for the MAOIs which are thought of as Powerful but Dangerous. Selections are primarily made based on side-effect profile.
However:
the MAOIs might not actually be all that powerful.
If you look at the numbers there does seem to be a practical difference in outcomes. The bottom-of-the-barrel medications - on average - require you to treat 4-5 additional patients to get one additional patient past that >50% reduction in symptoms scores (relative to placebo).
Antidopaminergics are treated as being either “strong” or “weak” and treatment is generally selected on symptom severity and side-effect profile.
Buuuuuuuuut, on average, meta-analyses indicate that the best of these medications only barely pushes patients over the line of minimal clinical improvement.
Wot’s uh… the deal here? Are psychiatrists just a collection of human beings with a limited capacity for accurate statistical reasoning, woefully prone to fads and superficial narratives about medications, doomed to make suboptimal choices for the rest of our lives?
I mean… Yes. Obviously.
Fortunately, Mother Nature has blessed us with the NMDA receptor, which allows us to take superficial, faddish narratives and replace them with slightly less superficial, slightly less faddish narratives that might better reflect reality (and maybe even be clinically useful?), so let’s see if we can’t come up with some of those in part 2.
Edit: Part 2 is here!
Wot's Uh... The Deal With How We Pick Antidepressants and Antipsychotics Pt. 2

This is the second part of an essay about the selection of antidopaminergics and antidepressants. In Part I, I outlined (what I see as) the prevailing attitude of psychiatrists towards their selection of antidepressants and antidopaminergics, and my uncertainty about the extent to which that was supported by the data. I went through two big meta-analyse…
My citation manager has 78 papers in the “antidopaminergics” folder, and 13 in the “antidepressants” folder
And in the running for the most unfortunate names for a class of drugs. Tranylcypromine is dangerously close to being cancelled. They also have some of the worst brand names I have ever heard. Nardil (phenelzine) sounds like a 3th grader’s attempt at an insult. Parnate (tranylcypromine) feels like it was named in the early 60s, because it was, just like its friends Miltown (meprobamate) and Midamor (amiloride). Emsam (selegiline) is at least fun to say, but just doesn’t have enough low-frequency letters to sound as as cool as Vraylar.
Seriously, if you’re a practicing psychiatrist, spend some time reading it.
There’s a good pun somewhere in here but damn if I can find it
Tricyclic antidepressant.
Let’s assume for now that HAM-D scores are a reasonable and clinically meaningful endpoint
Scores range from 0-30
I’m not going to write “on average” literally every time, so just insert “on average” every time I talk about a concrete number.
It’s important to note that this is not the same as giving them nothing. There is something powerful about giving people something they think is medicine.
Don’t be juvenile
Yes, same guy
For reference, a PANSS score ranges from 30-210 and are chunked into severity ranges. Mild: 58-74 / Moderate: 75-94 / Marked illness: 95 - 115 / Severe: >115
NNT has some shortcomings for psychiatric practice, as these medications work on a gradient, rather than a binary outcome like a cardiovascular event. Obtaining remission from depression, a dimensional illness, is distinct from meaningful improvement (which I know can be folded into response), whereas for say a statin LDL lowering is almost of no consequence except as for reducing the event of a stroke. It is also true that there can be improvements in person's life that are not captured by HAMS-D 17, and some things that don't matter, such as "insight into being ill."
I think the real interesting dive is into the specific measures that see improvement from the respective antidepressants - i.e. if agomelatine's effect size via is primarily reduced through sleep on HAM-D, then that is an important mediator for antidepressant selection. It can help one move into thinking about the type of depression and the network symptomatology for the person that is keeping them in a depressed state. It can also probably yield the true lack of meaningful efficacy for some of the agents we use - for example, if a participant is experiencing significant insomnia, this could correspond to a total of 6 points added to their HAM-D, as there are three questions about this with points 0-2. You could give a medication that improved insomnia dramatically just by sedating them (is this amitriptyline's secret sauce?) and move their HAM-D down by 3 points (1 point for each insomnia question), which corresponds to an effect size of 0.5. Their HAM-D would be improved but most people would not say this is a real targeting of depression, and could end up causing long term harm as the trial is only 6 weeks and the harm of disrupted sleep architecture, potential cognitive dulling, may only manifest over the long term.
It stinks that we lack a better or more valid construct - MDD is so poor and so it is no wonder that medication effects are going to be extremely noisy. At his point I have little curiosity for more MDD analysis; would much prefer to see analysis of the individuals in these trials who seem to get a high treatment response to which drug, looking at their specific depression profile along with what the drug modifies, in addition to other moderators and mediators.
Anyhoo, great work man!
Great article, thanks for writing and diving into the details of the research, Nils. Interesting to read from the perspective of a resident psychiatrist.